Comparing the current period to the prior period is relatively easy to accomplish in Essbase, and is often required when creating a Cash Flow hierarchy. Assume the following scenario.
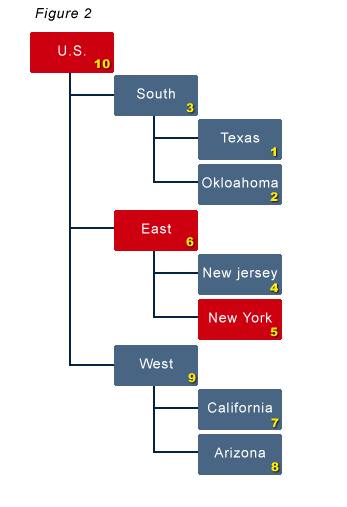
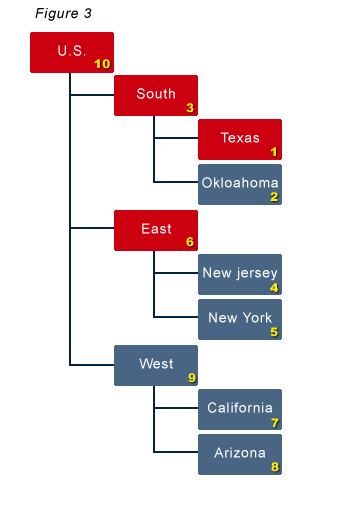
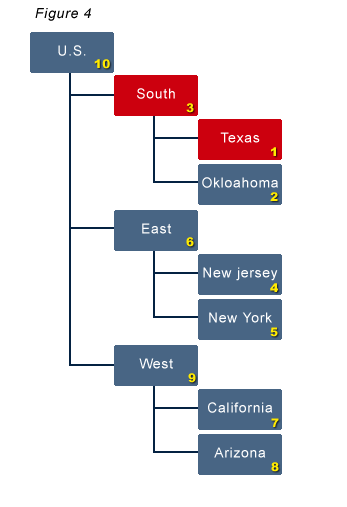
An outline exists that includes a Year and Time_Period dimension. The Year dimension includes 2007, 2008, and 2009. The Time_Period dimension includes Full Year, Quarter 1 through 4, and all 12 months. The dimension type for the Time_Period dimension has to be set to Time. A dimension named COA (chart of accounts) holds the general ledger account structure. Below is an example of the Time_Period dimension

To enable a dynamic approach to solving this problem and minimizing the maintenance required as new years are added, an understanding of the following two functions is required.
@PRIOR
The PRIOR function provides a way to compare a member outside of the Time_Period dimension in multiple Time_Period members. For example, accounts for July could be compared to June, or Quarter 2 could be compared to Quarter 1. There are two parameters that this function accepts. The first is the member to get the prior value for. The second is the number of periods you want to shift the comparison. If @PRIOR(“Asset123”,1) is used, it would provide the value for the period previous to what you had selected in the Time_Period member. So, if June was selected, it would provide the value for May. If the formula was @PRIOR(“Asset123”,2) and June was selected, the result would be the value for April (2 periods back). The function uses members at the same generation, so @PRIOR(“Asset123”,1) would provide the difference between Qtr2 and Qtr1 if Qtr2 was selected.
So, what happens if January or Qtr1 is selected? There is no previous member for these. This is where the second function comes in to play.
@MDSHIFT
MDSHIFT is similar to PRIOR, but it lets the calculation reference members across dimensions. Where PRIOR only allows references on one dimension, MDSHIFT allows references to move across multiple dimensions. If the user expects to see the different between Jan and Dec of the prior year or Qtr1 to Qtr4 of the prior year, MDSHIFT enables that to happen without hard coding the script. Again, the goal is to have a script that doesn’t need to be maintained.
MDSHIFT accepts a set of parameters. If your shift needs to occur along one dimension, it requires one set of parameters. If your shift needs to occur along more than one dimension, it will accept multiple sets. The function’s first parameter is the member you are evaluating, just like the PRIOR function. The next set of parameters is what can exist multiple times if you are shifting along multiple dimensions. The set consists of three parameters, of which the first two are required. The first of the set is the number of positions to shift. The second is the dimension to shift on. The third is a range of member to use to shift along. If this is left blank, Essbase uses level 0 members.
To get the prior value for Jan, or Dec of the previous year, it would be MDSHIFT(“Asset123″,-1,”Year”,,11,”Time_Period”,). The first parameter is the member to evaluate. The next two parameters are used to reference the previous member (-1) in the Year dimension. Since the Year dimension members are level 0, the fourth parameter is not required. The next series, or set, references Dec ( 11, or move forward 11 from Jan) of the Time_Period dimension. The last parameter is not required since we only want to reference level 0 members again.
Putting it all together
If we put these two functions together with a basic if/then/else statement, we get a dynamic formula that won’t need to be updated as we progress through time. It would look something like this:
If(@ISMBR(“Jan”))
/* if Jan, then we have to compare Jan in the current year to Dec [shift 11] in the prior year
[shift -1] */
“Asset123” – @MDSHIFT(“Asset123″,-1,”Year”,,11,”Time_Period”,);
ELSEIF(@ISMBR(“Qtr1”))
/* if Qtr1, then we have to compare Qtr1 in the current year to Qtr4 [shift 3] in the prior year
[shift -1]
The last parameter includes a range since we are not using level 0, which is the default */
” Asset123″ – @MDSHIFT(“Asset123″,-1,”Year”,,3,”Time_Period”,(“Qtr1″,”Qtr2″,”Qtr3″,”Qtr4”));
ELSEIF(@ISMBR(“YearTotal”))
/* if Year, then we have to compare to last year [shift -1] */
” Asset123″ – @MDSHIFT(“Asset123″,-1,”Year”,);
ELSE
/* all other members, which would include Feb through Dec */
” Asset123″ – @PRIOR(“Asset123”,1);
ENDIF;